Prisma ORM v5.17.0: QueryRaw performance improvements
Prisma ORM v5.17.0: QueryRaw performance improvements
We’ve changed the response format of queryRaw to decrease its average size, which reduces serialization CPU overhead. Here’s a peek at the results measuring before and after the improvements.
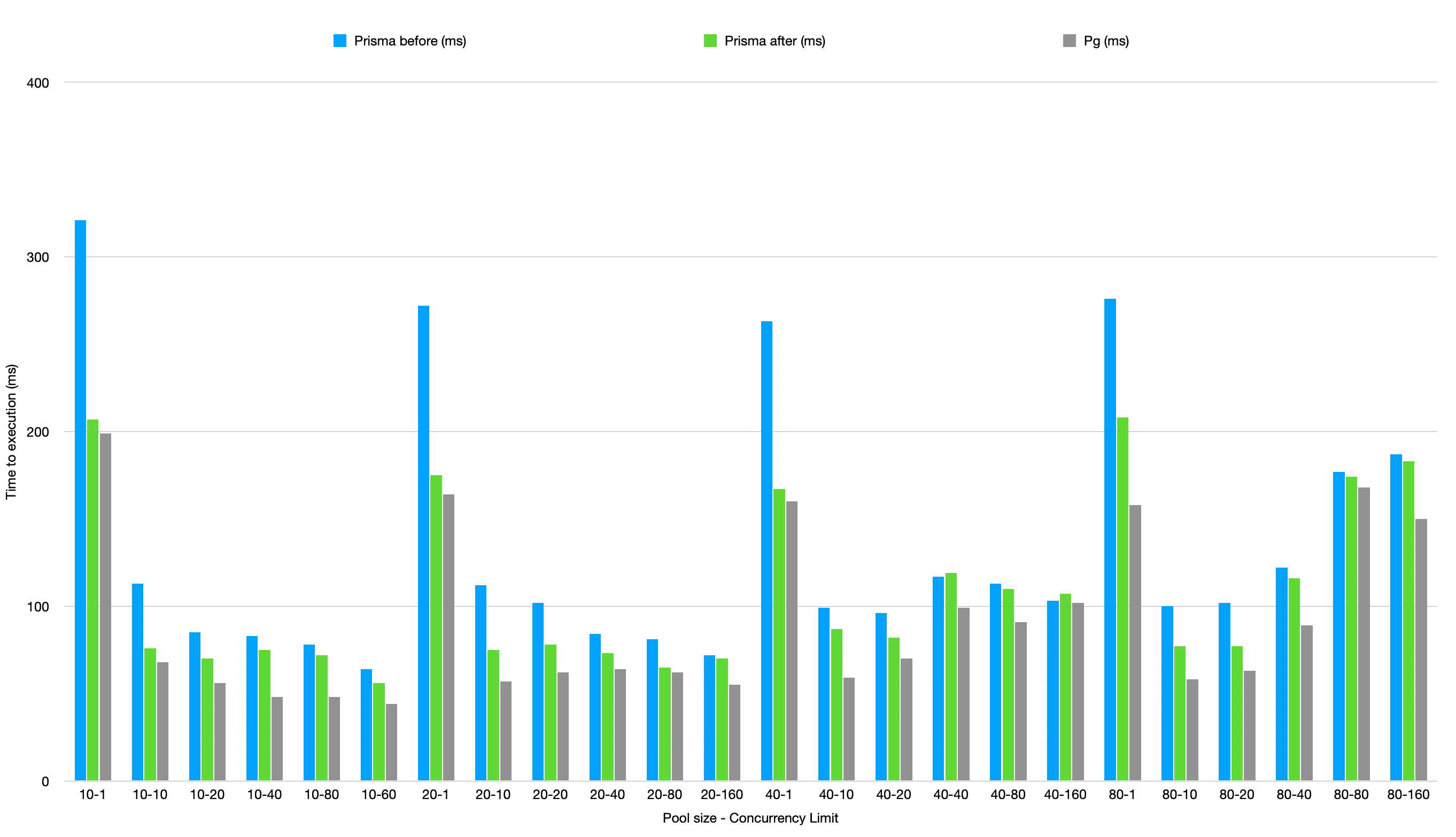
When querying large data sets, we expect you to see improved memory usage and up to 2x performance improvements, as you can clearly see in the graphs. We are very excited to introduce these improvements in our latest 5.17.0 release!
VSCode extension improvements
In 5.17, we introduced some quality of life improvements for our VS Code extension, which makes interacting with it so much better!
Some of the additions were:
- Find references across schema files
- Added context on hover
- Additional quick fixes
Find out more in our latest release notes.
Going beyond Prisma ORM
Already building with Prisma ORM? Explore how Prisma Accelerate and Prisma Pulse help you develop faster, more scalable applications with real-time features your users are looking for in our new docs page: Going Beyond Prisma ORM.
We take a look at common problems that arise as you're building applications, and how Accelerate and Pulse take your application to the next level after the Prisma ORM.
Check how Solin uses Prisma Accelerate to serve 2.5M database queries per day
Solin, a leading fitness marketplace for creators, has improved its platform by integrating Prisma Accelerate. This story highlights how Prisma Accelerate has contributed to Solin's success by enhancing performance and reliability with its scalable connection pool and global database cache.

Check out our blog post and learn more about their architecture and the fantastic results they have obtained with Accelerate!
Cloud connectivity report
As we run on AWS & Cloudflare, we collect extensive latency data between them. We think you'll find this data as interesting as we do, so we’re excited to share our 1st annual Cloud Connectivity report!
Read the report here and dive into all the nitty gritty about latency with us.